Every cyclist knows just how much of an effect the weather can have, especially wind. The wind speed and direction can mean the difference between flying along, effortlessly smashing KOMs, and realising that you have to keep pedalling to avoid going backwards!
Which makes it all the more surprising that Strava has no provision for weather information (and, as far as I know, no plans to add it).
So I though I would have a crack, then left it for a year thinking about how complex getting, storing and retrieving all the weather data would be. By chance, I then found a great weather API that would hugely speed up the project at World Weather Online. So here goes….
Essentially, it is a project of two halves :
- A server process to fetch Strava activities and weave weather data into them.
- Client side code to map an activity and display the route with weather information overlaid onto it.
This blog post will outline the server side code whilst the next one will describe the client.
Server side code - StravaWeatherServlet
Essentially, the principal job of the StravaWeatherServlet is to sit between the browser client and the Strava servers, relaying requests for Strava activity data, parsing them, fetching the weather information from World Weather Online for the correct time and locations, and adding this weather info to the activity data.
Following an authentication step, where the servlet requests a Strava access token, the client asks the servlet to get a list of activities to choose from.
When the user selects an activity, the client sends the servlet an ‘activity’ request with a unique activity ID. This is then used in the function ‘getStravaActivityWithWeather’ which issues the activity request to the Strava API.
The information is returned as JSON which looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | { "comment_count": 0, "segment_efforts": [ { "distance": 1038.3, "start_date_local": "2016-03-02T09:33:04Z", ... "segment": { "distance": 1041.8, "start_latlng": [ 53.424473, -2.217701 ], "end_latlng": [ 53.433642, -2.214634 ], "name": "1km Time Trial (N) - Parkville to Parsonage", ... }, "elapsed_time": 133, "moving_time": 133, "start_date": "2016-03-02T09:33:04Z" }, { "distance": 702.9, "start_date_local": "2016-03-02T09:33:52Z", "segment": { ... "start_latlng": [ 53.427669, -2.216579 ], ... "end_latlng": [ 53.433826, -2.214619 ], ... }, "name": "Money Saver to Parsonage Rd sprint", "elapsed_time": 88, "id": 12172204111, "pr_rank": null, "moving_time": 88, "start_date": "2016-03-02T09:33:52Z" }, ... ], "type": "Ride", "end_latlng": [ 51.32, -1.23 ], "kilojoules": 138.6, ... "max_speed": 12.6, "start_latlng": [ 53.42, -2.22 ], "name": "Morning Ride", ... "start_latitude": 53.42, "location_city": "Manchester", "elapsed_time": 1402, "average_speed": 6.203, "moving_time": 1291, "start_date": "2016-03-02T09:29:19Z", "calories": 154.6, ... } |
I have omitted some of the data here, but each activity consists of some general information; start and end co-ordinates and date-times and a list of ‘segment efforts’ each of which contains start date-times and co-ordinates. These provide a set of co-ordinates in time and space that we can use to fetch weather data.
On receiving the activity, we parse the JSON and look at each segment effort, extracting the “start_latlng” co-ordinates and the “start_date” date and time of that segment. We then use these to request weather information for a particular place and point in time.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | final JSONArray segmentEfforts = activity.getJSONArray("segment_efforts"); for (int i=0; i<segmentEfforts.length(); i++) { final JSONObject segmentEffort = segmentEfforts.getJSONObject(i); if (segmentEffort.has("segment") && segmentEffort.has("start_date")) { final long time = stravaDateFormat.parse( segmentEffort.getString("start_date") ).getTime(); final JSONObject segment = segmentEffort.getJSONObject("segment"); if (segment.has("start_latlng")) { final JSONArray startLatLng = segment.getJSONArray("start_latlng"); WeatherInfo weather = getWeatherInfoByTimeAndLocation( weatherAccessToken, time, startLatLng.getDouble(0), startLatLng.getDouble(1) ); if (weather!=null) { segment.put("weather",new JSONObject(weather)); } Thread.currentThread().sleep(200); } } } |
The function ‘getWeatherInfoByTimeAndLocation’ fetches weather data from api.worldweatheronline.com for a specific date and lat/long. The WorldWeatherOnline API returns a set of hourly weather observations from the weather station closest to the location and for the date requested. To prevent repeated requests about similar locations and times, the responses are cached on disk against co-ordinates formatted to 3 decimal places and the datetime to nearest day. The appropriate hourly observation is then selected from the response with the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | JSONArray hourly = weather.getJSONArray("hourly"); JSONObject curWeather = null; for (int i=0; i<hourly.length(); i++) { curWeather = hourly.getJSONObject(i); long curWeatherTime = dtFmt.parse(dateQuery+" "+curWeather.getString("time")+"00").getTime(); if (i==hourly.length()-1) //curWeather is the last observation, use that { break; } final JSONObject nextWeather = hourly.getJSONObject(i+1); long nextWeatherTime = dtFmt.parse(dateQuery+" "+nextWeather.getString("time")+"00").getTime(); if (time < nextWeatherTime) //requested time is between { //curWeather and nextWeather //select the closest observation to the requested time //default is curWeather if ((time-curWeatherTime)>(nextWeatherTime-time)) { curWeather=nextWeather; } break; } } |
This observation data is then added to the json for each of the segments (plus the start and end of the route). The result looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | ... "segment": { "country": "United Kingdom", "distance": 237.7, "city": "Manchester", "end_longitude": -2.233929, "end_latitude": 53.473518, "start_latlng": [53.471899, -2.234528], "elevation_low": 41, "starred": false, "end_latlng": [53.473518, -2.233929], "name": "Campus Link Path (Reverse)", "weather": { "temp": 4, "windChill": -3, "description": "Light sleet showers", "windDirDeg": 294, "windDir": "WNW", "iconURL": "http://cdn.worldweathe...sleet_showers.png", "time": 0, "windSpeed": 43 }, "id": 5785697, "state": "England" }, |
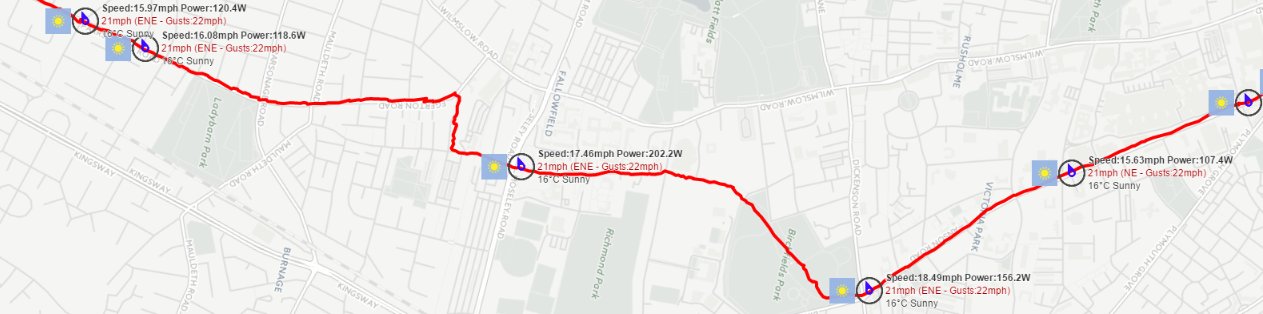
This extra weather information is used by the AJAX front-end code to plot the weather information on a map along with some segment information. (More about this in the next blog post).
All source and webapp code for this project is here. You will need to edit the following files to make it work:
1) WEB-INF/web.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <servlet> <servlet-name>StravaWeatherServlet</servlet-name> <servlet-class>io.wiretrip.stravaweather.StravaWeatherServlet</servlet-class> <init-param> <param-name>webapp_path</param-name> <param-value>http://127.0.0.1:8082/stravaweather/</param-value> </init-param> <init-param> <param-name>strava_client_id</param-name> <param-value>xxxx</param-value> </init-param> <init-param> <param-name>strava_client_secret</param-name> <param-value>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx</param-value> </init-param> <init-param> <param-name>weather_api_token</param-name> <param-value>xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx</param-value> </init-param> </servlet> |
You will need to set the webapp_path to that of your deployment. The strava_client_id and strava_client_secret are assigned to your application by Strava in the Manage Applications section at Strava Developers . Likewise, when you register for API access at World Weather Online you will be given an access token which you need to enter for weather_api_token.